Programming With Types in C#
This is a transcript of a recent talk that I gave during Level Up Week, Redgate’s internal conference.
The idea behind this talk comes from learning about types while at Portland State University. We all find different subjects that resonate with us. For me, the idea of defining errors out of existence with the type system struct me as important. Why should I, a software engineer, have to hold extra information about my program in my head? Compilers are smart pieces of code, and they can keep track of more information at a time that I can; why not encode facts about my programs such that a compiler can verify things for me?
Throughout this article, when I mention specific data types I’ll be speaking directly about C#’s type system.

What even is a type?
I know it’s cliche to start a presentation or article with a definition, but I think it’s important that we all agree on what we’re talking about.
Types describe the allowed values that a particular variable can have. If I
have a value with the type int I know that value will be an integral value in
the range -2,147,483,648 to 2,147,483,647. Likewise, a uint will hold an
unsigned integral value in the range 0 to 4,294,967,295. Some data types, like
string, are more complex: a string holds zero or more Unicode graphemes or
null.
Types also describe the allowed operations that can be performed on a particular variable in a program. We’ll get to that in a bit.
I’d like to introduce you to an example class that represents a server:
public class Server {
public string Name { get; }
public string IpAddress { get; }
public Server(string name, string ipAddress) {
Name = name;
IpAddress = ipAddress;
}
}
This class tells me that two strings identify a server, and those two strings can be any allowed string. Are any of the following servers valid in the real world?
var s1 = new Server(null, null);
// imagine the entire text of A Tale of Two Cities is the ipAddress
var s2 = new Server("💩", "It was the best of times");
var s3 = new Server("localhost", "127.0.0.1");
Based on the definition of our class, all three of these are perfectly fine
servers. Our program would compile, but who knows what would happen at runtime
when we attempt to connect to a null IP address.
More importantly, we know that the definition of Server is incorrect.
RFC-1123 says that a hostname must be ASCII (specifically, only the
lower 7-bits of ASCII are allowed). Likewise, IPv4 addresses have a
well-defined format, they’re not arbitrary strings. With this information at
hand, I’ll take a stab at refining the Server class.
public class Server {
public [DisallowNull] string Name { get; }
public [DisallowNull] string IpAddress { get; }
public Server([DisallowNull] string name, [DisallowNull] string ipAddress) {
Name = name;
IpAddress = ipAddress;
}
}
This new vision of a server tells me a little bit more. Two strings identify a
server, and neither of those strings can be null. This is some progress. (We
can, of course, get the same effect by using C# 8’s nullable reference types
feature, but I wanted to make the lack of null explicit here.)
// This no longer compiles!
// var s1 = new Server(null, null);
// But this pile of 💩 still does
var s2 = new Server("💩", "It was the best of times");
var s3 = new Server("localhost", "127.0.0.1");
We’ve defined null values out of existence for the Server class, but it’s
still possible to use both an invalid hostname and an invalid IP address. I’ll
address the IP address first by using the IPAddress class. This
ensures that whoever is using our Server class has verified that the IP
address is correct.
using System.Net;
public class Server {
public [DisallowNull] string Name { get; }
public [DisallowNull] IPAddress IpAddress { get; }
public Server([DisallowNull] string name, [DisallowNull] IPAddress ipAddress) {
Name = name;
IpAddress = ipAddress;
}
}
By using the IPAddress type on both the property and argument, we’re saying
that consumers of this class must ensure that the IP address being used is
both non-null and a valid member of the IPAddress type. We’ve achieved some
level of victory - in our original example, only s3 is a valid Server!
// This no longer compiles!
// var s1 = new Server(null, null);
// But this pile of 💩 will no longer compile!
// var s2 = new Server("💩", "It was the best of times");
var s3 = new Server("localhost", "127.0.0.1");
Unfortunately, we could still create a server with a valid IP address and 💩 as the hostname. There’s one more refinement needed to this class: we need to make sure that the hostname is only in the range of values allowed by RFC-1123. To keep things simple, I will artificially limit the space we’re working with to Netbios names.
using System.Net;
public class Server {
public [DisallowNull] NetbiosName Name { get; }
public [DisallowNull] IPAddress IpAddress { get; }
public Server([DisallowNull] NetbiosName name,
[DisallowNull] IPAddress ipAddress) {
Name = name;
IpAddress = ipAddress;
}
}
At this point, we’ve defined a type that says a server is identified by a
Netbios name and an IP address, so long as they both are not null. To be more
robust, we might poke around in System.Net until we find a more flexible type
than NetbiosName, but I think this works for the purposes of this example.
When thinking about a type, it can be helpful to think about the type as a house or building. We want the type to describe only the values that belong. Picking the correct data types as we design our own type ensures that I only represent valid data in my program. This also has the side effect of documenting interfaces, as much as it’s possible, through code.
Self-documenting code
Rather than wax eloquent on my vision of self-documenting code, I’m going to build a vision of self-documenting code step-by-step. Quick question, though: what does the following code tell you about itself?
public object foo(object o)
It’s tempting to compare this to the identity function (that would be
public T id(T t)). From the definition of foo, we don’t know what that
function does and we would have to read the documentation (assuming the
developer wrote any) or read the actual code. Neither of those situations is
ideal. Documentation is important, but we need to remember that the first piece
of documentation that any developer encounters is the function signature.
Creating self-documenting code, step-by-step
In this next section, I’m going to take you on a journey where we take a piece of pseudocode and refine it into a strongly-typed piece of self-documenting code.
int? GetLicenseCount(Server server)
We know that GetLicenseCount takes a Server (which is identified by a
NetbiosName and IPAdress). The surprising result is the nullable int as
return value. We have to either read documentation or else infer meaning from
this return type. Ultimately, this raises questions like:
- What does it mean to have
nulllicenses? - What about having zero licenses?
- What does a negative result mean?
- What does the number even mean at this point?
If this were production code (which it isn’t), I would have to seek out the
documentation to understand what int? means. If there was no documentation,
for some reason, I would have to dig into the source code to understand the
meaning behind int?.
In a perfect world, we would be able to encapsulate any valid response from a
call as a type. When constructed explicitly and using types, we can
represent all valid responses of GetLicenseCount as something called a “sum
type” or “discriminated union”. (C# is eventually going to get
support for disrciminated unions, but support is also available via
language-ext. I’ll be working in plain old C# here.)
// We don't want to instantiate a "raw" license count
public abstract class LicenseCount {}
// If you don't have any licenses, let's make that happen
public sealed class Unlicensed : LicenseCount {}
// Likewise, let's make it possitle to represent an infinity of licenses
public sealed class UnlimitedLicense : LicenseCount {}
// Finally we get to a countable number of licenses
public sealed class LimitedLicense : LicenseCount {
// Just an enumeratino for "per seat" and "per CPU"
public LicenseUnit LicenseUnit;
public uint LicenseCount;
}
// Which lets me change the original function to
LicenseCount GetLicenseCount(Server server)
Looking at the above code, we can now tell a lot about what’s happening just from the types we’ve given our data.
- A server consists of a valid, non-null Netbios name and a valid, non-null IP address.
- There are three kinds of license: unlicensed, unlimited licenses, and a limited license.
- The limited license is a count of licenses and a description of the thing to count.
The GetLicenseCount function now mostly documents itself using our new
LicenseCount class hierarchy. Some documentation might be warranted if
there’s weird math going on behind the scenes, but this is otherwise clear. As
a side effect, consumers of GetLicenseCount will have to pattern match over
the return type. I like to think of this as extra insurance that developers (me
in two weeks) will do the right thing with the return type. By encoding
additional information in the type, the code prevents a 0 indicating “no usable
licenses” from being confused with a 0 indicating a “you need to give us money
so you’ll have licenses”.
Phantom Types
Phantom types were something I first discovered while learning about typestate analysis. Typestate analysis isn’t important here, but what is important is that we can use a phantom type to encode extra information about our types to better describe the program that’s executing. Rust by Example has a good explanation:
A phantom type parameter is one that doesn’t show up at runtime, but is checked statically (and only) at compile time.
Data types can use extra generic type parameters to act as markers or to perform type checking at compile time. These extra parameters hold no storage values, and have no runtime behavior.
N.B. While the phantom type parameter is erased in Rust, it’s still present in C#.
Reviewing the LicenseCount that I created previously, I can see that I’ve
made a critical mistake. It’s possible do some silly things with a
LicenseCount that won’t get caught until the code throws a runtime exception,
which is precisely what we’re trying to avoid. Don’t believe me?
var serverLicenseCount = new LimitedLicense {
LicenseCount = 12,
LicenseUnit = LicenseUnit.Server
};
// Ignore just how bad this pattern is, OK?
// I'm making a point.
var userCount = GetUserLicenses(serverLicenseCount);
I’m sure you, dear reader, noticed the mistake I made in passing a
LimitedLicense for a server to the GetUserLicenses function. In a larger
change, this error might not be so easy to spot. In theory, code review should
catch this problem. And, in theory, we could make GetUserLicenses throw a
runtime exception. But I’d like to make it so incorrect code can’t even compile.
Step 1: The phantom type
In the original LimitedLicense class, the enumeration discriminates the type
of license (per server or per user). Instead of using an enumeration, we can
move the license into a type!
public abstract class LicenseUnit {}
public sealed class UserLicense : LicenseUnit {}
public sealed class ServerLicense : LicenseUnit {}
Step 2: Limiting LimitedLicense
Now I can limit the LimitedLicense even further using the power of generics:
public sealed class LimitedLicense<TLicenseUnit> : LicenseCount
where TLicenseUnit : LicenseUnit
{
public uint LicenseCount;
}
Step 3: Typing the method
At this point, all of the important information about what kind of license someone has is encoded in the type. Now that the kind of license is part of the type, it is impossible to do the wrong thing and try to get the user license count for a server-based license:
public uint GetUserLicenses(LimitedLicense<UserLicense> l)
{
return l.LicenseCount;
}
// This will compile
var ul = new LimitedLicense<UserLicense> { LicenseCount = 42 };
var x = GetUserLicenseCount(ul);
// This will not compile
var sl = new LimitedLicense<ServerLicense> { LicenseCount = 42 };
var y = GetUserLicenseCount(sl);
There’s a slight naming problem: GetUserLicenseCount implies the existence of
similarly named functions for the other subclass of LicenseCount. While it’s
tempting to create a function that accepts any subclass of LicenseCount,
that’s a good idea.
- What number should that function return for an
UnlimitedLicense? It can’t returnDouble.PositiveInfinitybecause theLimitedLicenseis storing the number of licenses as an unsigned integer. - What number should that function return for an
Unlicensed? It can’t return
0 because 0 is a number and someone might add 1 to 0 and then theUnlicenseduser will suddenly have a license. - It’s not a great idea to use a switch here because there is no built-in way (that I know of) to make sure that pattern matches over types include all possible subclasses.
The solution, it turns out, is easier than you might think: overloads!
public uint GetLicenseCount(LimitedLicense<UserLicense> l)
{
// Do something awesome
}
public uint GetLicenseCount(LimitedLicense<ServerLicense> l)
{
// Do something awesome, but different
}
Passing anything other than LimitedLicense will fail compilation.
Unrepresentable states (the count of infinite licenses) can’t be represented in
the program. Things that should be counted can still be counted. If I add a new
license type, I don’t have to worry about that new type falling through the
switch and triggering an exception (because it’s common to add exceptions to
the default case) or, worse, doing something unexpected.
One last example: data validation
At the beginning of the last section I mentioned that I first encountered the idea of phantom types while learning about typestate analysis. In typestate analysis types get decorated with additional state (that’s still part of the type) to ensure that programs aren’t doing things like writing to uninitialized memory. The typestate is a state machine of allowed states; functions in the program only accept types that are in the correct typestate. This prevents the programmer from doing things like writing to uninitialized memory or trying to read past the end of a file.
I’m going to demonstrate how we can turn form validation into a workflow enforced by C#’s type system. C# doesn’t support typestate analysis, but it turns out that we can get the benefits of typestate analysis using phantom types.
I’m going to start off with a very simple system. Assume that form data can be in one of three states:
- Unvalidated
- Validated
- Invalid
From here, it’s obvious that I can create a phantom type to represent these three states of a form:
public abstract class ValidationStatus {}
public sealed class Unvalidated : ValidationStatus {}
public sealed class Valid : ValidationStatus {}
public sealed class Invalid : ValidationStatus {}
I am assuming that the data I want comes from a string. What’s going on here
really doesn’t matter, but what we do know is that we can’t trust the contents
until they’ve been validated. But, first, we have to make a form!
public class FormData<TStatus> where TStatus : ValidationStatus
{
// Making this private prevents someone else from making a FormData
// that breaks the rules.
private FormData () { /* ... */ }
// Parse a string and make something that we don't trust.
public static FormData<Unvalidated> MakeFormData(string formData) { /* ... */ }
}
I need a way to validate the FormData. While it’s possible to parse the
string in the constructor for FormData that would leave me in the unenviable
position of having to throw an exception in the constructor. Instead, I’ve
created a FormData<Unvalidated>. It doesn’t make sense to submit unvalidated
data and, as I’ll show in a little bit, the submit function will only accept a
FormData<Valid>.
I can get from unvalidated data to validated data like this:
public class FormData<TStatus> where TStatus : ValidationStatus
{
// Making this private prevents someone else from making a FormData
// that breaks the rules.
private FormData () { /* ... */ }
// Parse a string and make something that we don't trust.
public static FormData<Unvalidated> MakeFormData(string formData) { /* ... */ }
public static Either<FormData<Invalid>, FormData<Valid>>
Validate(FormData<Unvalidated> formData)
{
// do something interesting
}
}
When a particular FormData is goes through the Validate function, I want to
take appropriate action based on whether or not the FormData is valid or
invalid. Rather than throw an exception for flow control, I will use an
Either type as the return from Validate. Either is used to represent the
result of computation that is either correct or an error. From the Haskell
documentation of Either: “by convention, the Left
constructor is used to hold an error value and the Right constructor is used
to hold a correct value (mnemonic: “right” also means “correct”).” By using
Either I’m returning a meaningful value to the consumer of Validate;
Either lets the consumer know that this function could error.
Here’s what validating FormData might look like:
var fd = FormData.MakeData(theData);
// fd is now FormData<Unvalidated>
var result = FormData.Validate(fd);
// now we can look at the Either and react appropriately
if (result.IsLeft) {
var invalid = result.Left();
// TODO: tell the user what they did wrong
} else {
var valid = result.Right();
// Assuming that we have:
// public void Submit(FormData<Valid> data)
Submit(valid);
}
What do I get from all of this? FormData<T> can use some internal
representation of data that nobody needs to know about. All developers need to
know is that a FormData is constructed it from a string and that, because
of the construction of Submit, there’s no way to submit data in any state
other than Valid. Callers must first validate form data before submitting it;
a FormData<Valid> cannot be constructed apart from through the functions
provided. Finally, only data in the appropriate state can move through the
program.
It’s also easy to add new validation status to ValidationStatus:
public abstract class ValidationStatus {}
public sealed class Unvalidated : ValidationStatus {}
public sealed class InProgress : ValidationStatus {}
public sealed class Completed : ValidationStatus {}
public sealed class Valid : ValidationStatus {}
public sealed class Invalid : ValidationStatus {}
And then enforce those new states in code:
public class FormData<TStatus> where TStatus : ValidationStatus
{
// Making this private prevents someone else from making a FormData
// that breaks the rules.
private FormData () { /* ... */ }
// Parse a string and make something that we don't trust.
public static FormData<Unvalidated> MakeFormData(string formData) { /* ... */ }
public static FormData<InProgress> SaveProgress(FormData<Unvalidated> formData) { /* ... */ }
public static FormData<InProgress> SaveProgress(FormData<InProgress> formData) { /* ... */ }
public static FormData<Completed> CompleteForm(FormData<InProgress> formData) { /* ... */ }
public static Either<FormData<Invalid>, FormData<Valid>>
Validate(FormData<Completed> formData)
{
// do something interesting
}
}
And now our program has encoded a state machine in our types. It becomes easy to add more states by adding additional subclasses of the abstract base class. It becomes straightforward to refactor the program and I know that when the program compiles, data will move from between the appropriate states. If the program doesn’t compile… well, I’ve made the compiler into a state machine validator and I can use the errors to make it easy to find and fix mistakes.
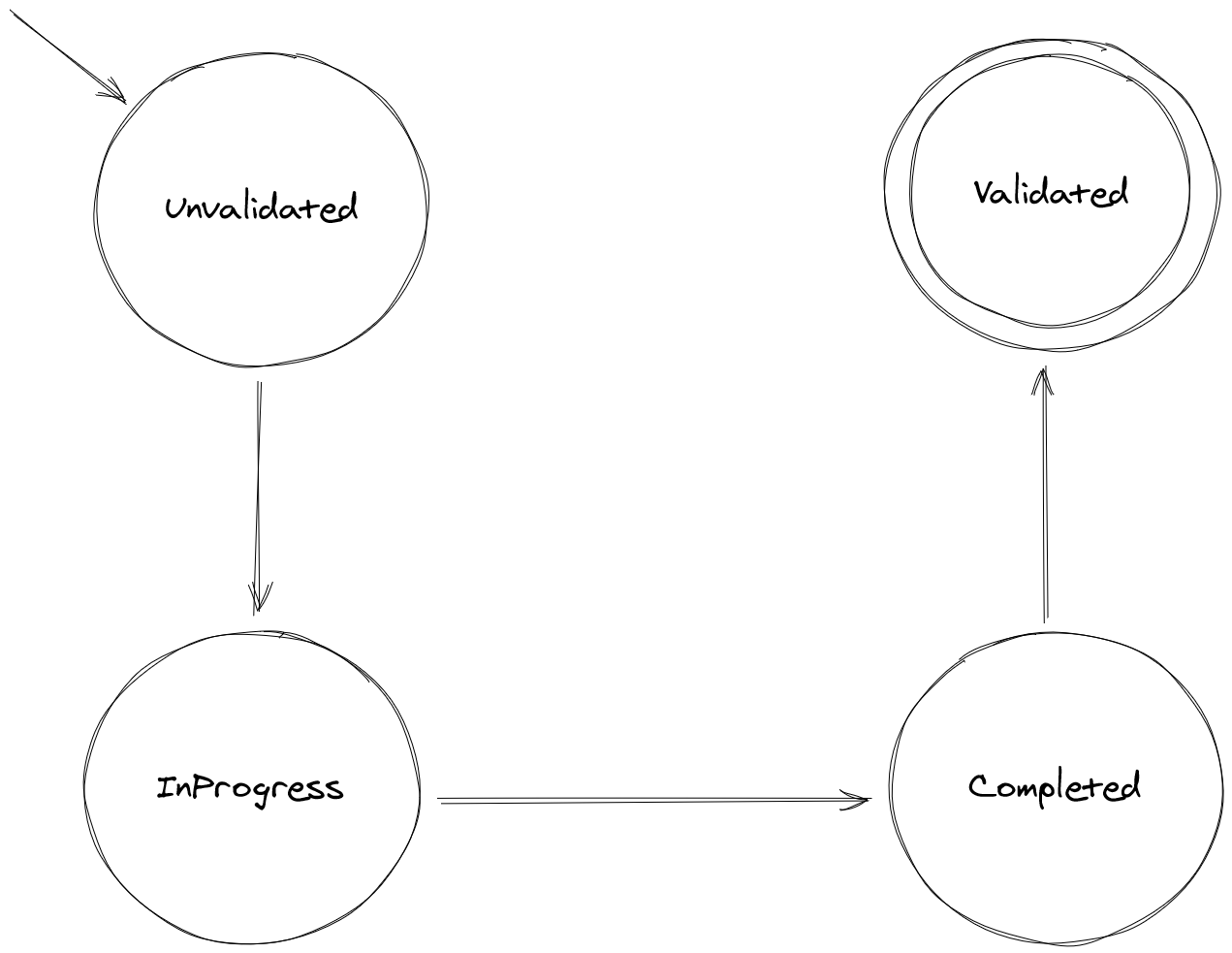
Here we mave a state machine diagram showing data coming into the Unvalidated
state before moving to InProgress, then Completed, and finally the Validated
state. Not pictured is the possibility of moving from InProgress to InProgress.
Limiting functionality
We’re almost to the end, I promise… But first, I’m going to limit functionality even more.
The LicenseCount example already worked to limit functionality. That makes
makes sense. After all, types limit functionality by describing what’s
allowable. In the case of the LicenseCount I’ve made it possible to only
compare to license counts when they are:
- The same type
- And of the same generic type.
Which really means that I can’t go ahead and compare a user-based license to a server-based license. This code below won’t compile:
var uc = new LimitedLicense<UserLicense> { LicenseCount = 42 };
var sc = new LimitedLicense<ServerLicense> { LicenseCount = 42 };
// This won't compile, they're not the same type!
var same = (uc == sc);
Since my fancy LimitedLicense is just a wrapper around a uint it stands to
reason that I can wrap other less strict types to make stricter types.
Usernames are strings. But there are some limitations to how programmers should
interact with usernames:
- It doesn’t make sense to use a
StartsWithon usernames. - Likewise, other developers shouldn’t be taking arbitrary substrings of usernames.
- Or even just using less than/greater than (this is less clear, but stay with me).
I’m going to limit the usefulness of usernames in my (fictitious) application by creating a class just for usernames:
public sealed class Username
{
private readonly string _username;
public Username(string username)
{
_username = username;
}
}
If I want to compare two Usernames, what do I really want to compare? I want
to compare whatever the identifying bits are for a Username. This might be
the string of the actual username, a precomputed hash, or something else. The
important bit is that I don’t want any way to accidentally compare the wrong
chunks of data in the program. To solve this, I’m going to use an Id<T>.
What’s an Id<T>? In this case, it’s an arbitrary type that exists only to
compare two Ts.
public sealed class Id<T> : IEquatable<Id<T>>
where T : IIdentifiable
{
private readonly int _id;
public Id(T t)
{
_id = t.Identify();
}
public bool Equals(Id<T> other)
{
return id == other._id;
}
// TODO: Don't forget to implement Equals(Object) and GetHashCode()
}
What’s IIdentifiable? I made it up. It’s some interface we have that produces
the unique identifying bits of an object. The idea behind using an Id<T> and
an IIdentifiable is to push the concept of comparison out to an
implementation that only deals with the idea of equality comparison.
Username never needs to implement IEquatable directly or, better, we can
make direct comparison of Usernames always return false and get developers
to always use Id<Username> for the comparison.
Wrapping up
We learned a few things on this journey. One is that types limit what a program
can do by describing a set of allowed values and defining a set of allowed
operations. Types also add to the richness of code; the type Username is more
descriptive than string. These richer type names also provide some built-in
documentation when reviewing code.
Effective use of types can add the benefit of eliminating unrepresentable states. In the licensing example, the state machine we create prevents a developer from submitting invalid form data. If a developer does try to do submit bad data, the program won’t compile. Types can turn runtime errors into compilation failures, letting us catch errors before they reach users.
Of course, this comes at a cost. Data must be poked and prodded to ensure that it’s in the right shape to pass through the program. At each stage, the developer has to make decisions about how to work with the possibility of error. The examples get more complex as the article progresses. With richness of types, code may begin to feel more complex.
This is a trade-off: as software engineers we can choose the level of rigor to apply to our programs. By carefully and selectively considering where we use stronger and richer types we can apply Postel’s principle and be conservative in what we do and liberal in what we accept from others.
Photo by Amy Shamblen on Unsplash
